Extended Reality (XR) offers a powerful way to support human collaboration by making digital information spatial, embodied, and situated. By aligning interaction with physical and social context, XR can enhance shared awareness, coordination, and group work beyond what screen-based interfaces allow. Yet collaborative work in real-world settings remains complex, involving fragmented information, dynamic environments, and evolving goals.
My research explores how AI-augmented XR systems can help address these challenges. I design and study XR systems that integrate spatial interaction with perception, multimodal language models, and agent-based workflows to support human–agent collaboration. Through system building and empirical studies, I investigate how XR + AI can improve context awareness, decision-making, and traceability in collaborative work across meetings, hybrid events, and other shared activities.
2026

S-TIER: Situated-Traceable Insights in Extended Reality for Hybrid Crisis Management
Cheng-Yao Wang, et al.
Under review
We present S-TIER, a framework and prototype that convert crisis-team conversation and multimodal context into situated, traceable XR insights to support hybrid and asynchronous response work.
Crisis response teams collaborate in hybrid settings, coordinating under time pressure. Remote participants often lack access to wall displays that anchor situational awareness, leading to fragmented context and uneven participation. These challenges are compounded by asynchronous workflows, where team representatives join mid-session and rely on overviews to catch up. We investigate these gaps through a multi-stage study with crisis management experts. From formative interviews and an exploratory hybrid XR prototype, we distilled design goals around shared context, overview preparation, and traceability. We then propose the \framework{} framework, which transforms conversations into situated and traceable insights that retain links to their original sources. A proof-of-concept prototype realizes this framework by combining multimodal context capture, structured insight extraction, and situated visualization, evaluated in simulated crisis scenarios with two remote response teams. Findings highlight design considerations for asynchronous participation, adaptive summarization, and traceability, advancing pathways toward real-world deployment of hybrid XR crisis systems.
# XR # LLM/VLM # Collaboration # Human-Agent-Interaction
S-TIER: Situated-Traceable Insights in Extended Reality for Hybrid Crisis Management
Cheng-Yao Wang, et al.
Under review
TL;DR: We present S-TIER, a framework and prototype that convert crisis-team conversation and multimodal context into situated, traceable XR insights to support hybrid and asynchronous response work.
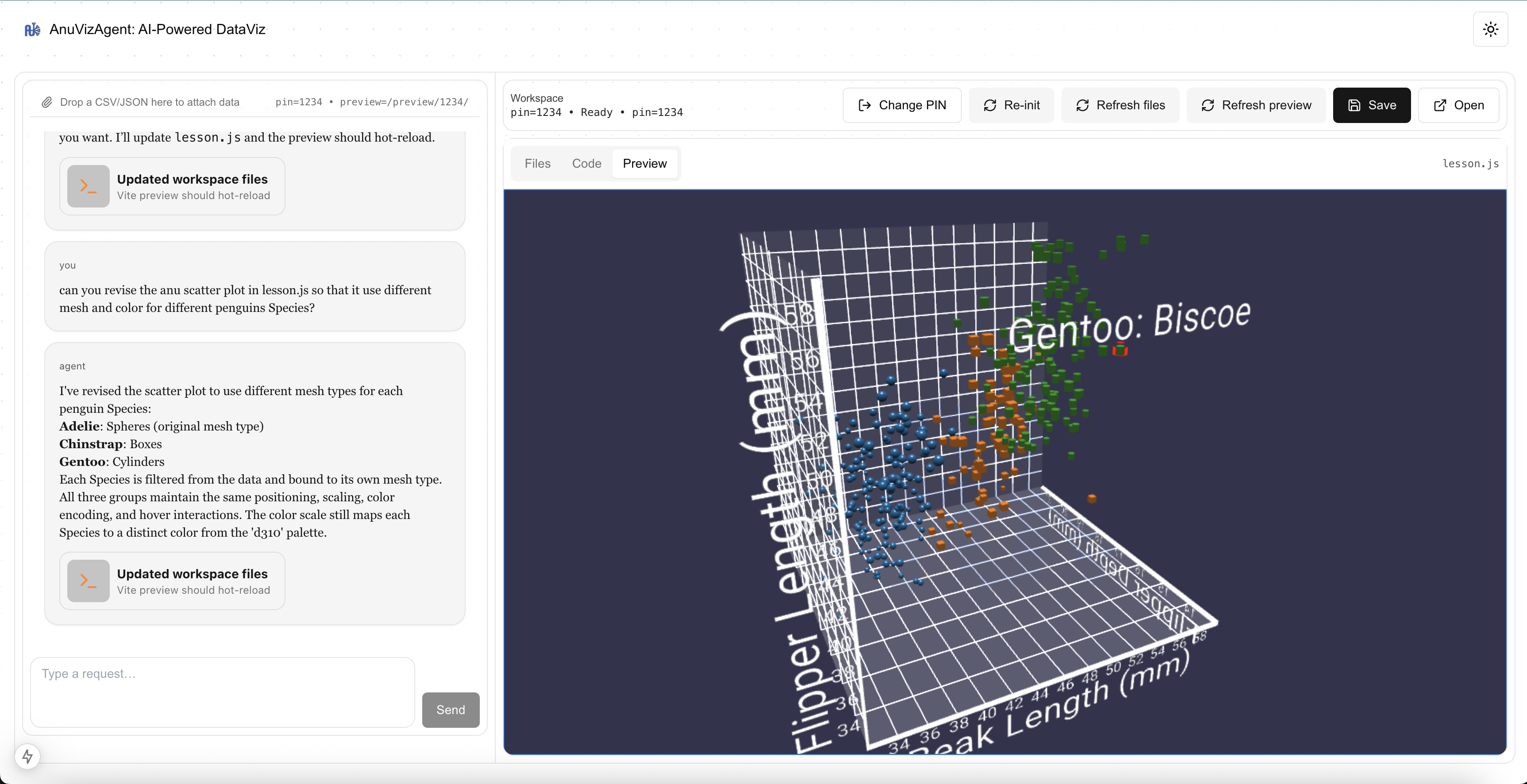
AnuVizAgent: A Live AI-Driven Workflow for Immersive Visualization
Cheng-Yao Wang
Ongoing Research Project
AnuVizAgent enables users to transform raw data into immersive WebXR visualizations through natural language interaction, with AI agents generating live, executable visualization code.
Creating immersive visualizations typically requires significant expertise in graphics, web development, and XR frameworks, posing a high barrier for exploratory data analysis. This project explores an interactive workflow that enables users to transform raw datasets into immersive, web-based visualizations through natural language interaction. Users begin by uploading structured data (e.g., CSV or JSON) and iteratively describing desired visual outcomes in a chat interface. An AI agent translates these high-level intents into executable Anu.js and Babylon.js code, which is injected into a live Vite development server and rendered in real time with hot reloading. Crucially, the same visualization is accessible across devices: users can refine results on a desktop browser and seamlessly view the identical, continuously updated scene in a WebXR-enabled headset such as Apple Vision Pro via a shared HTTPS endpoint. By combining AI-assisted code generation, live web visualization, and device-agnostic delivery, AnuVizAgent lowers the barrier to creating and exploring immersive data representations.
# XR LLM/VLM # Human-Agent Interaction
AnuVizAgent: A Live AI-Driven Workflow for Immersive Visualization
Cheng-Yao Wang
Ongoing Research Project
TL;DR: AnuVizAgent enables users to transform raw data into immersive WebXR visualizations through natural language interaction, with AI agents generating live, executable visualization code.
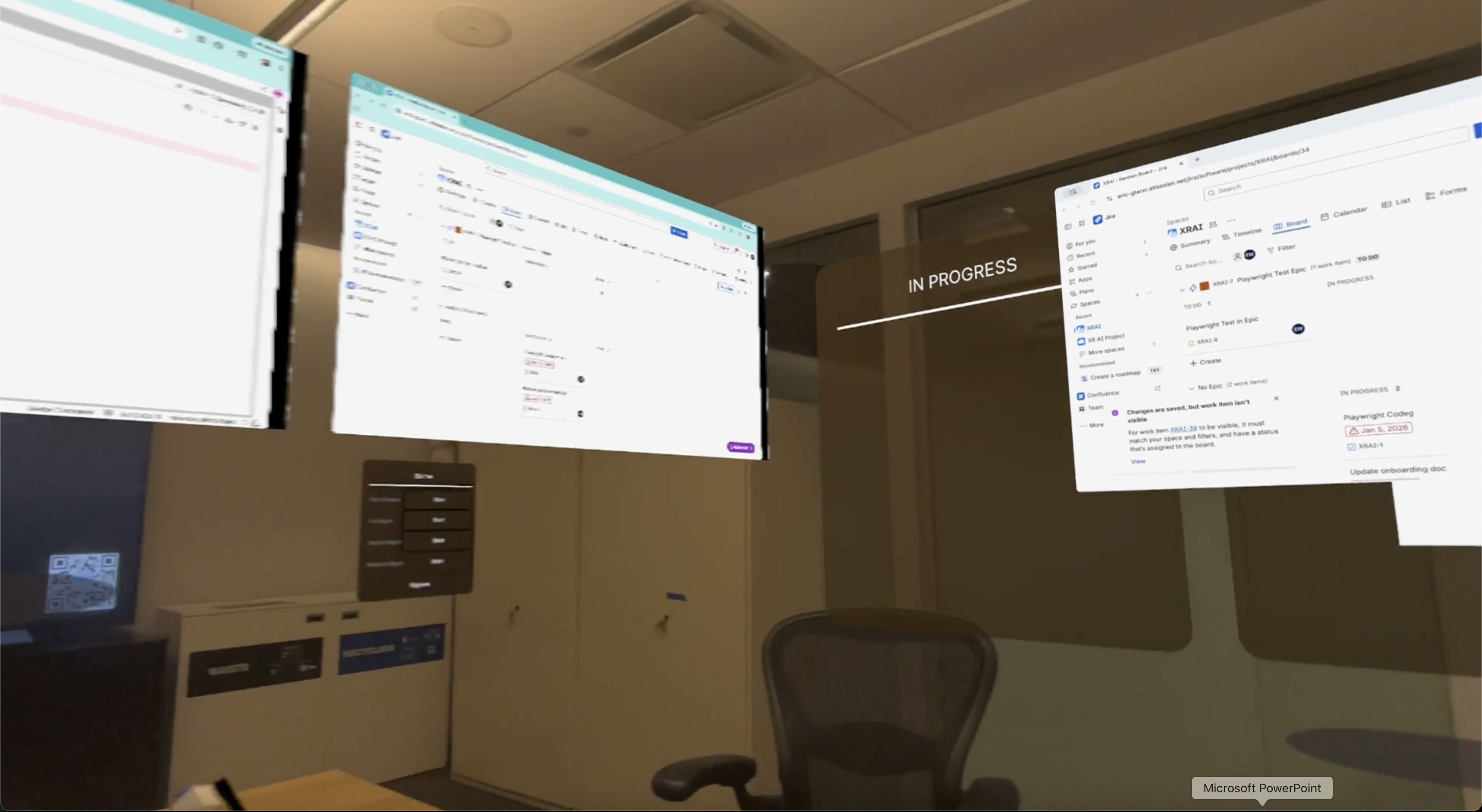
From Discussion to Action: Delegated Work in XR Team Meetings
Cheng-Yao Wang
Ongoing Research Project
This project explores how XR meetings can support delegated work during the meeting itself, enabling agents to carry out bounded tasks in parallel without disrupting group interaction.
Team meetings often involve identifying actionable tasks but require participants to defer execution until after the meeting or to multitask in ways that fragment attention and collaboration. This project investigates how Extended Reality (XR) team meetings can support delegated work during the meeting itself, without requiring participants to step out of the shared interaction. We explore a new interaction paradigm in which shared windows in XR meetings are augmented with agent capabilities that can carry out bounded tasks in parallel under human oversight. Leveraging XR-specific affordances—such as spatial organization, visibility, and non-verbal cues—we study how agents can identify actionable intent, request input in minimally disruptive ways, and make execution progress visible to the group. Through system design and empirical studies, this work examines how in-meeting delegation reshapes collaboration dynamics, feedback loops, and meeting practices, informing the design of future XR-based collaborative workspaces.
# XR # Collaboration # Agents # LLM/VLM # Human-Agent-Interaction
From Discussion to Action: Delegated Work in XR Team Meetings
Cheng-Yao Wang
Ongoing Research Project
TL;DR: This project explores how XR meetings can support delegated work during the meeting itself, enabling agents to carry out bounded tasks in parallel without disrupting group interaction.
2025

HybridPortal: Enabling Hybrid Group Interactions in Hybrid Events
Cheng-Yao Wang, et al.
Under review
HybridPortal introduces a mobile, portal-based system that bridges physical and virtual event spaces, enabling shared group interactions and social engagement between in-person and remote attendees.
Hybrid events are increasingly prevalent, offering in-person and remote participation to enhance inclusivity and sustainability. However, they often fail to create cohesive experiences, leaving remote participants feeling disconnected from in-person interactions. We present HybridPortal, a novel system that transforms a large monitor into a movable portal, bridging virtual and physical event spaces. By streaming AR video from the physical venue, HybridPortal allows remote attendees to interact with in-person attendees and view the surrounding physical environment as in-person attendees move the portal through the venue, while in-person attendees navigate and engage with remote attendees in the virtual space. We deployed HybridPortal at a hybrid conference, implementing hybrid group activities to explore its impact on social interactions. Our findings demonstrate how HybridPortal’s mobility and cross-realm interactions enhance social presence, facilitate group engagement, and inform the design of future hybrid systems. We contribute insights into leveraging spatial dynamics and hybrid group interactions to create more cohesive and engaging social experiences for hybrid events.
# XR # Computer Vision # Collaboration
HybridPortal: Enabling Hybrid Group Interactions in Hybrid Events
Cheng-Yao Wang, et al.
Under review
TL;DR: HybridPortal introduces a mobile, portal-based system that bridges physical and virtual event spaces, enabling shared group interactions and social engagement between in-person and remote attendees.
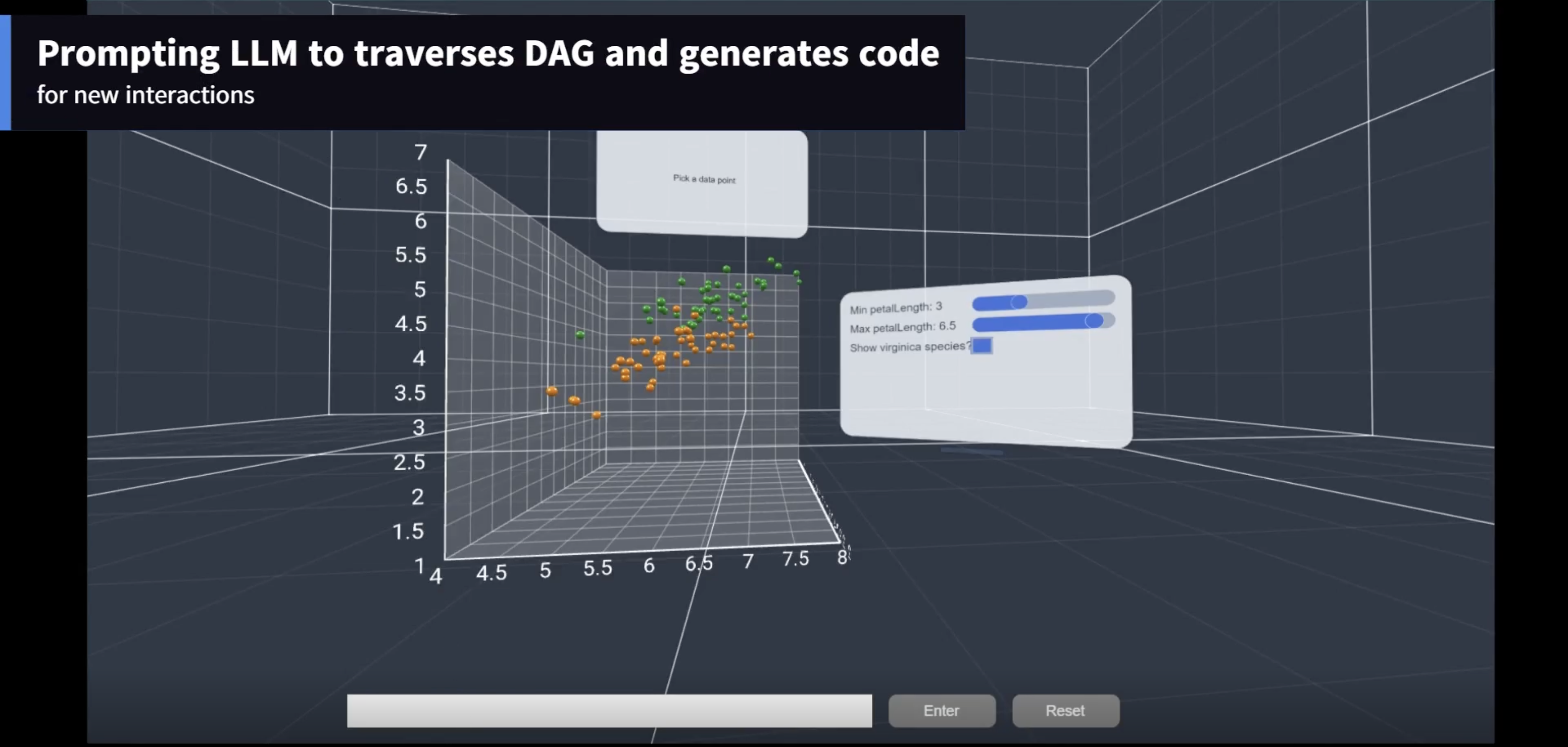
XRCopilot: A Lightweight and Generalizable Approach for Conversational Interaction in XR
Cheng-Yao Wang
Research Prototype
XRCopilot enables conversational interaction in XR by automatically exposing application logic and interaction context to language models through a lightweight, code-driven approach.
We present XRCopilot, a lightweight and generalizable approach for enabling conversational interaction in Extended Reality (XR) environments, including Virtual Reality (VR), Augmented Reality (AR), and Mixed Reality (MR). Instead of relying on application-specific instrumentation or handcrafted interaction schemas, XRCopilot leverages a TypeScript transformer built on the TypeScript Compiler API to automatically extract function comments, source code, and call stacks during user interactions in XR applications. These signals are continuously organized into a Directed Acyclic Graph (DAG) that captures the structure of user interactions at runtime. Each node in the DAG represents a function invocation together with its semantic and implementation context, allowing language models to reason about user actions, system state, and interaction history. By grounding conversational agents directly in application execution, XRCopilot provides a scalable foundation for building XR conversational interfaces that are transparent, adaptable, and reusable across XR systems.
# XR # LLM/VLM
XRCopilot: A Lightweight and Generalizable Approach for Conversational Interaction in XR
Cheng-Yao Wang
Research Prototype
TL;DR: XRCopilot enables conversational interaction in XR by automatically exposing application logic and interaction context to language models through a lightweight, code-driven approach.

SocialMiXR: Facilitating Hybrid Social Interactions at Conferences
Cheng-Yao Wang*, Fannie Liu*, William Moriarty, Feiyu Lu, Usman Mir, David Saffo, Mengyu Chen, Blair MacIntyre
PACM HCI (CSCW 2025)
SocialMiXR demonstrates how aligning physical and virtual spaces using WebXR can enable shared social activities and foster meaningful interaction between in-person and remote conference attendees.
[Abstract] [DOI] [Paper] [Video]
Hybrid options at conferences, which support in-person and remote attendance, have increasingly become the norm in order to broaden participation and promote sustainability. However, hybrid conferences are challenging, where in-person and remote attendees often have disjoint, parallel experiences with limited opportunity to interact with each other. To explore the potential for facilitating social interaction between in-person and remote conference attendees, we designed and built SocialMiXR, a research prototype that uses WebXR technologies to align the physical and virtual worlds into one hybrid space for socialization. We deployed SocialMiXR in a three-day field study with 14 in-person and remote attendees of an engineering conference. Our qualitative results demonstrate that participants felt they were together in the same conference experience and formed meaningful connections with each other. At the same time, they faced difficulties balancing different realities and capabilities given their separate contexts. We discuss implications for the design of hybrid social experiences at conferences.
# XR # Collaboration
SocialMiXR: Facilitating Hybrid Social Interactions at Conferences
Cheng-Yao Wang*, Fannie Liu*, William Moriarty, Feiyu Lu, Usman Mir, David Saffo, Mengyu Chen, Blair MacIntyre
PACM HCI (CSCW 2025)
TL;DR: SocialMiXR demonstrates how aligning physical and virtual spaces using WebXR can enable shared social activities and foster meaningful interaction between in-person and remote conference attendees.

Growing Together at Work: Cultivating a Mentorship Garden
Erica Principe Cruz, Cheng-Yao Wang, William Moriarty, Blair MacIntyre, Fannie Liu
PACM HCI (CSCW 2025)
Mentorship Garden explores how XR-based counterspaces can support sustained workplace mentorship by fostering reflection, comfort, and long-term relationship building for historically marginalized employees.
Workplace mentorship is critical for career advancement, sense of belonging, and well-being. However, historically marginalized groups face barriers to effective mentorship including misaligned commitments, difficulty establishing comfort with mentors, and challenges in sustaining relationships. We explore how 3D virtual environment (VE) counterspaces—spaces that center the well-being of marginalized people—can help address these barriers and create dedicated environments for workplace mentorship. We present Mentorship Garden, a digital counterspace designed to facilitate mentorship communication around commitments, goals, progress, and well-being. We deployed Mentorship Garden with 10 mentor–mentee pairs recruited from DEI mentoring programs at a large global company and interviewed participants about their experiences. Results show that Mentorship Garden provided a relaxing and supportive space for mentorship rituals, while also revealing challenges in integrating such systems into everyday workplace practices. We discuss design implications for creating virtual mentorship counterspaces and opportunities for future research.
# XR # Collaboration
Growing Together at Work: Cultivating a Mentorship Garden
Erica Principe Cruz, Cheng-Yao Wang, William Moriarty, Blair MacIntyre, Fannie Liu
PACM HCI (CSCW 2025)
TL;DR: Mentorship Garden explores how XR-based counterspaces can support sustained workplace mentorship by fostering reflection, comfort, and long-term relationship building for historically marginalized employees.
2024
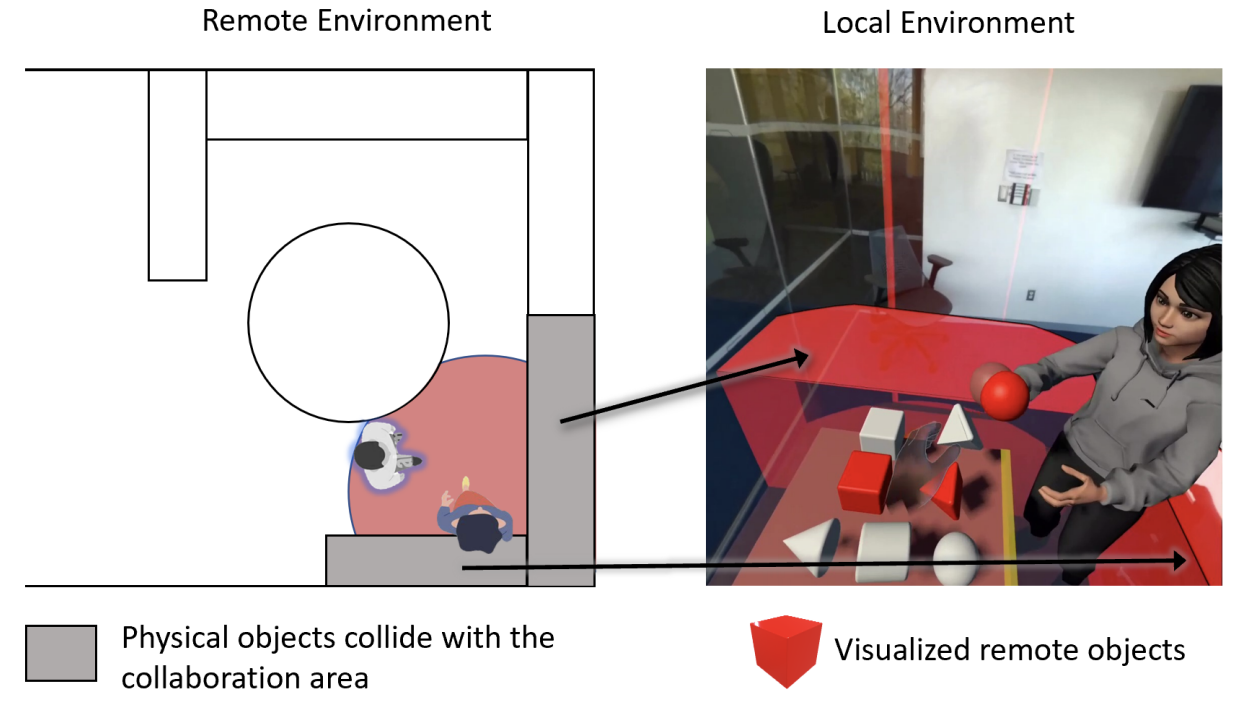
MRTransformer: Transforming Avatar Non-verbal Behavior for Remote MR Collaboration in Incongruent Spaces
Cheng-Yao Wang, Hyunju Kim, Payod Panda, Eyal Ofek, Mar Gonzalez-Franco, Andrea Stevenson Won
ISMAR Adjunct 2024
MRTransformer introduces techniques for transforming avatar non-verbal behavior so that collaborators can preserve pointing, gaze, and gesture meaning when working in physically incongruent mixed reality spaces.
[Abstract] [DOI] [Paper] [Video]
Physical restrictions of the real spaces where users are situated present challenges for remote XR and spatial computing interactions using avatars. Users may not have sufficient space in their physical environment to duplicate the physical setup of their collaborators. However, simply relocating avatars can break the meaning of one-to-one motions and non-verbal cues. We propose MRTransformer, a technique that uses weighted interpolations to guarantee that collaborators look at and point to the same objects locally and remotely, while preserving the meaning of gestures and postures that are not object-directed (e.g., close to the body). We extend this approach to support locomotion and near-space interactions such as grabbing objects, exploring the limits of social and scene understanding while enabling more flexible uses of inverse kinematics (IK). We discuss limitations and applications of this approach and open-source AvatarPilot to support broader use in mixed reality collaboration systems.
# XR # Collaboration
MRTransformer: Transforming Avatar Non-verbal Behavior for Remote MR Collaboration in Incongruent Spaces
Cheng-Yao Wang, Hyunju Kim, Payod Panda, Eyal Ofek, Mar Gonzalez-Franco, Andrea Stevenson Won
ISMAR Adjunct 2024
TL;DR: MRTransformer introduces techniques for transforming avatar non-verbal behavior so that collaborators can preserve pointing, gaze, and gesture meaning when working in physically incongruent mixed reality spaces.
AvatarPilot: Decoupling One-to-One Motions from Their Semantics with Weighted Interpolations
Cheng-Yao Wang, Eyal Ofek, Hyunju Kim, Payod Panda, Andrea Stevenson Won, Mar Gonzalez-Franco
ISMAR Adjunct 2024
AvatarPilot decouples raw avatar motion from semantic intent, enabling flexible transformation of pointing, gaze, and locomotion behaviors across physically constrained mixed reality spaces.
[Abstract] [Abstract] [DOI] [Paper] [Video]
Physical restrictions of the real spaces where users are situated present challenges to remote XR and spatial computing interactions using avatars. Users may not have sufficient space in their physical environment to duplicate the physical setup of their collaborators. However, when avatars are relocated to accommodate space constraints, one-to-one motions may no longer preserve their intended meaning. We propose AvatarPilot, a system that uses weighted interpolations to decouple low-level avatar motion from higher-level semantic intent. This approach ensures that collaborators look at and point to the same objects locally and remotely, while preserving non-object-directed gestures and postures near the body. We extend this technique to support locomotion and direct interactions in near space, such as grabbing objects, enabling more flexible use of inverse kinematics (IK). We discuss applications and limitations of this approach and release AvatarPilot as an open-source toolkit to support future mixed reality collaboration systems.
# XR # Collaboration
AvatarPilot: Decoupling One-to-One Motions from Their Semantics with Weighted Interpolations
Cheng-Yao Wang, Eyal Ofek, Hyunju Kim, Payod Panda, Andrea Stevenson Won, Mar Gonzalez-Franco
ISMAR Adjunct 2024
TL;DR: AvatarPilot decouples raw avatar motion from semantic intent, enabling flexible transformation of pointing, gaze, and locomotion behaviors across physically constrained mixed reality spaces.
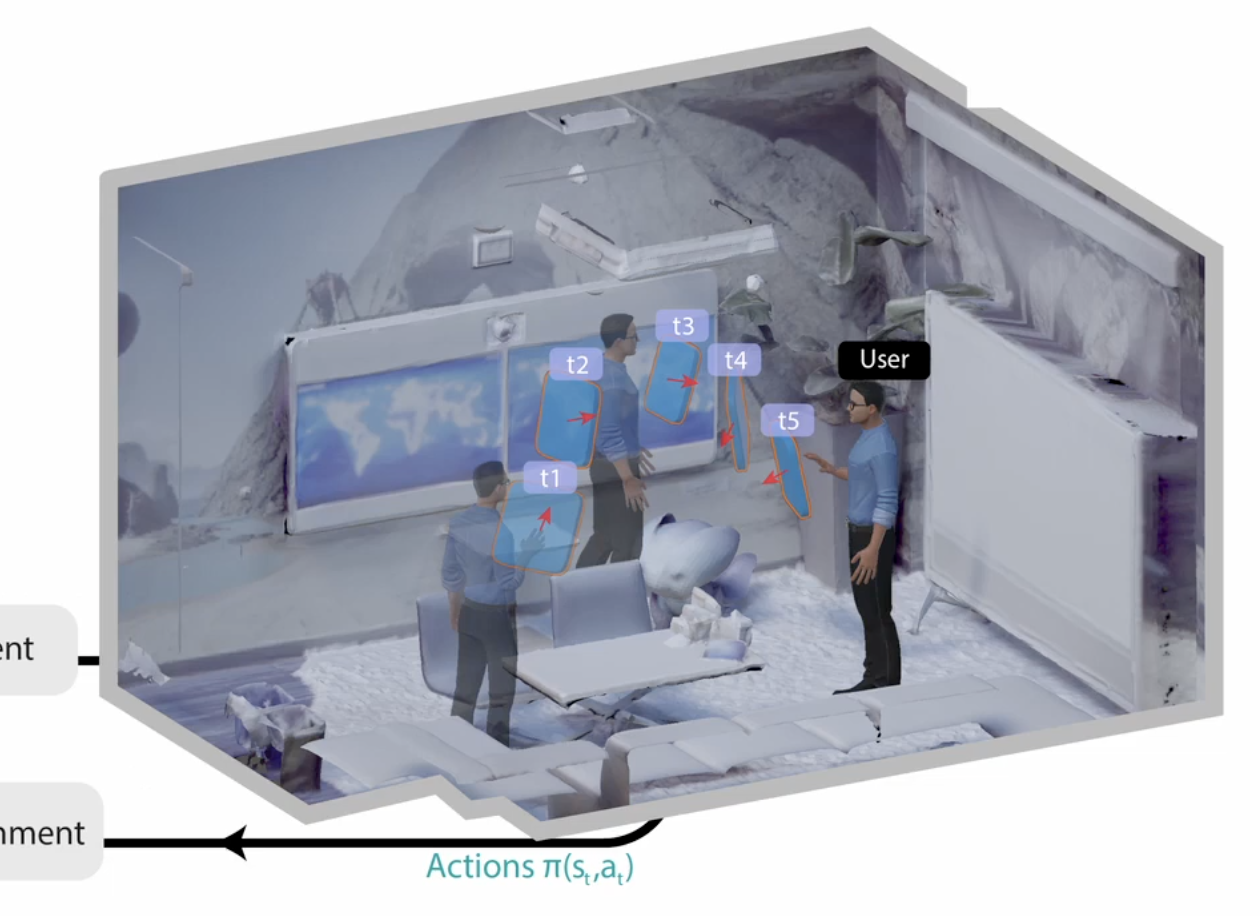
Adaptive 3D UI Placement in Mixed Reality Using Deep Reinforcement Learning
Feiyu Lu, Mengyu Chen, Hsiang Hsu, Pranav Deshpande, Cheng-Yao Wang, Blair MacIntyre
CHI EA 2024
This work explores how reinforcement learning can enable continuous, context-aware 3D UI placement in mixed reality environments that adapt to user pose and surroundings over time.
[Abstract] [DOI] [Paper] [Video]
Mixed Reality (MR) systems can support user tasks by integrating virtual content into the physical environment, but determining where and how to place this content remains challenging due to the dynamic nature of MR experiences. In contrast to prior optimization-based approaches, we explore how reinforcement learning (RL) can support continuous 3D content placement that adapts to users’ poses and surrounding environments. Through an initial exploration and preliminary evaluation, our results demonstrate the potential of RL to position content in ways that maximize user reward during ongoing activity. We further outline future research directions for leveraging RL to enable personalized and adaptive UI placement in mixed reality systems.
# XR
Adaptive 3D UI Placement in Mixed Reality Using Deep Reinforcement Learning
Feiyu Lu, Mengyu Chen, Hsiang Hsu, Pranav Deshpande, Cheng-Yao Wang, Blair MacIntyre
CHI EA 2024
TL;DR: This work explores how reinforcement learning can enable continuous, context-aware 3D UI placement in mixed reality environments that adapt to user pose and surroundings over time.
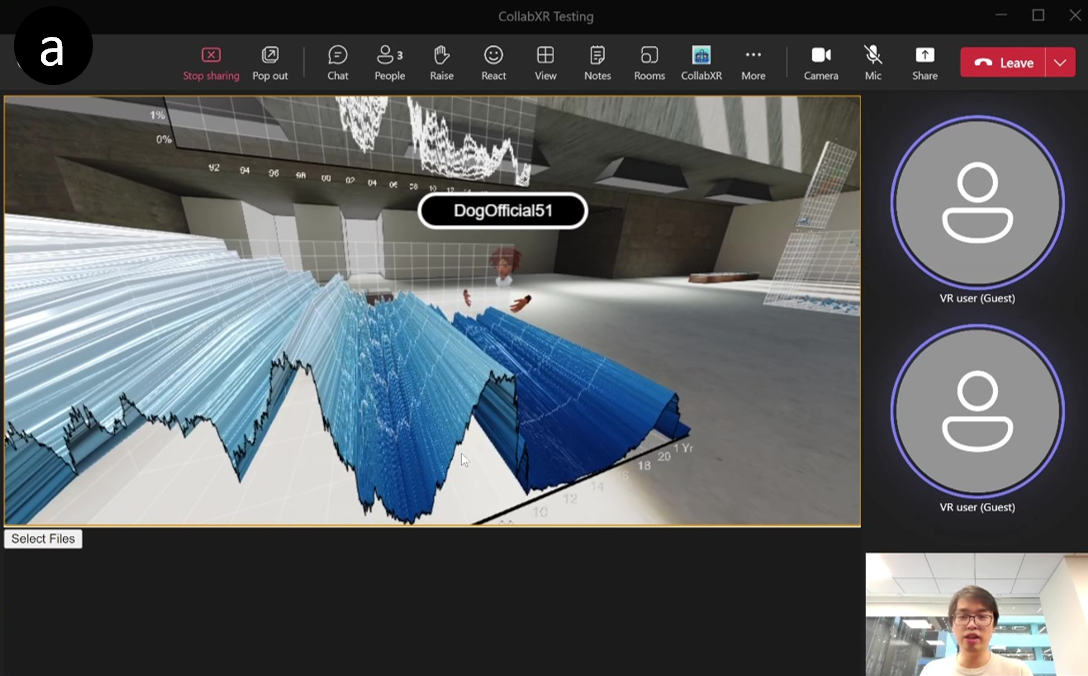
CollabXR: Bridging Realities in Collaborative Workspaces with Dynamic Plugin and Collaborative Tools Integration
Cheng-Yao Wang, David Saffo, Bill Moriarty, Blair MacIntyre
IEEE VRW 2024
CollabXR introduces a modular, open-source XR workspace that supports dynamic plugin-based tool integration for cross-reality collaborative work across heterogeneous platforms.
Hybrid meetings are often constrained by the limitations of videoconferencing, resulting in fragmented collaboration and reduced social presence. Extended Reality (XR) technologies offer immersive spaces that better support non-verbal communication and shared context for both remote and co-located participants. As Mixed Reality platforms become more accessible, cross-reality and platform-agnostic collaboration is increasingly common, but introduces communication asymmetries across devices and interaction modalities. This paper presents CollabXR, an open-source framework built with Babylon.js, WebXR, and Colyseus, designed to support research on cross-reality collaboration. CollabXR features a runtime plugin system that enables dynamic integration of custom code and data, and seamless interoperability with existing collaboration and communication tools. The system serves as a flexible research platform for developing and evaluating interaction techniques that address collaboration asymmetries when full symmetry across realities is not achievable.
# XR # Collaboration
CollabXR: Bridging Realities in Collaborative Workspaces with Dynamic Plugin and Collaborative Tools Integration
Cheng-Yao Wang, David Saffo, Bill Moriarty, Blair MacIntyre
IEEE VRW 2024
TL;DR: CollabXR introduces a modular, open-source XR workspace that supports dynamic plugin-based tool integration for cross-reality collaborative work across heterogeneous platforms.
2023
Embodying Physics-Aware Avatars in Virtual Reality
Yujie Tao, Cheng-Yao Wang, Andrew D. Wilson, Eyal Ofek, Mar Gonzalez-Franco
CHI 2023
This work shows that incorporating physics-aware corrections into self-avatar motion can improve embodiment in VR, even when strict one-to-one motion mapping is relaxed.
[Abstract] [DOI] [Paper] [Video]
Embodiment toward an avatar in virtual reality (VR) is generally stronger when there is a high degree of alignment between the user’s motion and the self-avatar’s motion. However, strict one-to-one motion mapping can produce physically implausible behaviors during interaction, such as body interpenetration or lack of physical response to collisions. We investigate how adding physics-based corrections to self-avatar motion impacts embodiment, despite introducing discrepancies between user and avatar motion. We conducted an in-lab study (n = 20) in which participants interacted with obstacles using physics-aware and non-physics avatars. Results show that physics-responsive avatars improved embodiment compared to no-physics conditions, in both active and passive interactions. These findings suggest that preserving physical realism can outweigh strict motion correspondence in supporting avatar embodiment.
# XR
Embodying Physics-Aware Avatars in Virtual Reality
Yujie Tao, Cheng-Yao Wang, Andrew D. Wilson, Eyal Ofek, Mar Gonzalez-Franco
CHI 2023
TL;DR: This work shows that incorporating physics-aware corrections into self-avatar motion can improve embodiment in VR, even when strict one-to-one motion mapping is relaxed.
2022

CityLifeSim: A High-Fidelity Pedestrian and Vehicle Simulation with Complex Behaviors
Cheng-Yao Wang, Oron Nir, Sai Vemprala, Ashish Kapoor, Eyal Ofek, Daniel McDuff, Mar Gonzalez-Franco
IEEE ICIR 2022
CityLifeSim is a configurable urban simulation system that models rich pedestrian and vehicle behaviors, enabling realistic multi-agent scenarios and synthetic data generation for vision and tracking research.
[Abstract] [DOI] [Paper] [Video]
Simulations are powerful tools for studying safety-critical scenarios, yet modeling complex temporal events involving pedestrians and vehicles in urban environments remains challenging. We present CityLifeSim, a high-fidelity simulation system designed for the research community, emphasizing rich pedestrian behaviors driven by individual personalities, environmental events, and group goals. The system supports diverse behaviors such as jaywalking, waiting for buses, interacting in crowds, and maintaining interpersonal distances, as well as large-scale crowd creation and management. CityLifeSim is highly configurable and enables the generation of unlimited scenarios with detailed logging. As a demonstration, we generated a multi-view dataset using 17 cameras, including street-level, vehicle-mounted, and drone-based views under varying weather conditions. We evaluate this dataset on pedestrian detection and identification tasks using state-of-the-art multi-object tracking methods, highlighting both the opportunities and limitations of synthetic data for urban perception research.
# Computer Vision
CityLifeSim: A High-Fidelity Pedestrian and Vehicle Simulation with Complex Behaviors
Cheng-Yao Wang, Oron Nir, Sai Vemprala, Ashish Kapoor, Eyal Ofek, Daniel McDuff, Mar Gonzalez-Franco
IEEE ICIR 2022
TL;DR: CityLifeSim is a configurable urban simulation system that models rich pedestrian and vehicle behaviors, enabling realistic multi-agent scenarios and synthetic data generation for vision and tracking research.
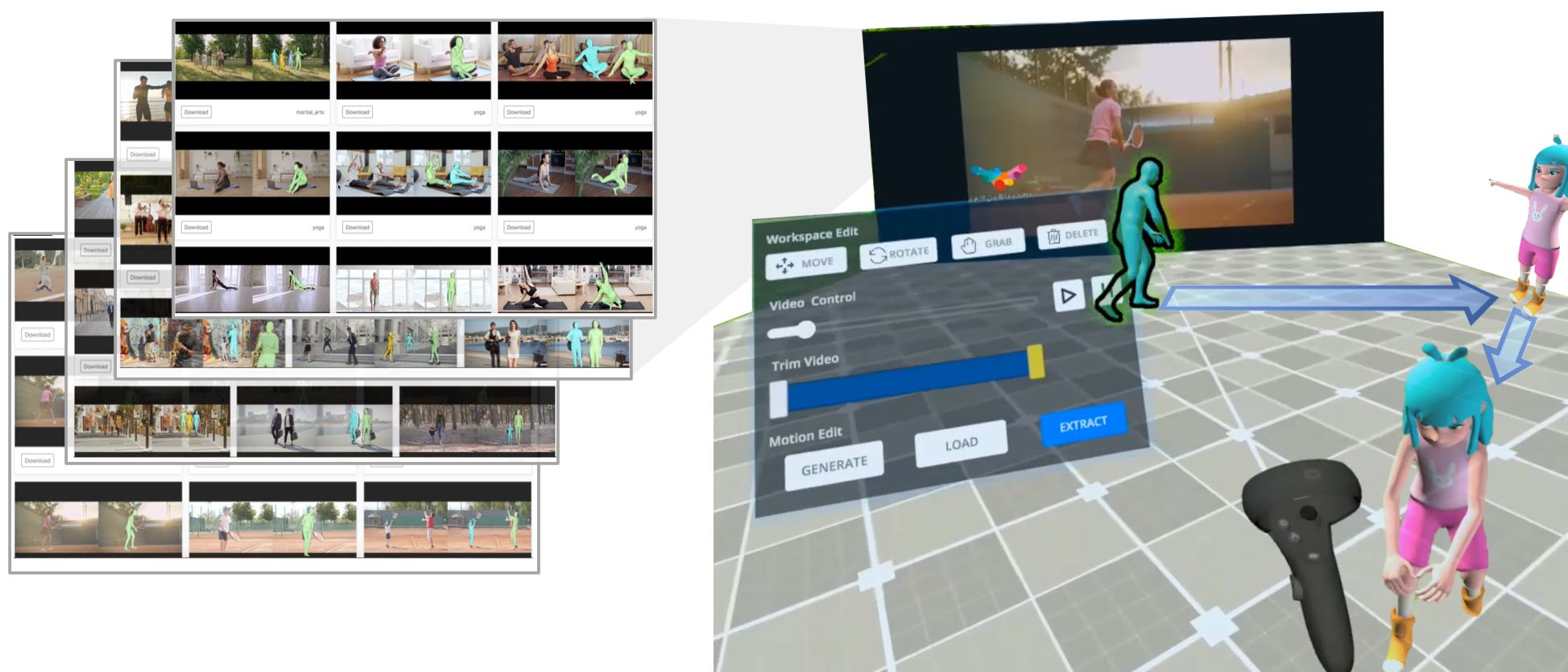
VideoPoseVR: Authoring Virtual Reality Character Animations with Online Videos
Cheng-Yao Wang, Qian Zhou, George Fitzmaurice, Fraser Anderson
PACM HCI (ISS 2022)
VideoPoseVR enables VR users to author character animations by reconstructing 3D human motion from online videos.
[Abstract] [DOI] [Paper] [Video]
We introduce VideoPoseVR, a system that allows users to animate VR characters using human motions extracted from online videos. We demonstrate an end-to-end workflow that allows users to retrieve desired motion from 2D videos, edit the motion, and apply it to virtual characters in VR. \VPVR leverages deep learning-based computer vision techniques to reconstruct 3D human motions from videos and enable semantic searching of specific motions without annotating videos. Users can edit, mask, and blend motions from different videos to refine the movement. We implemented and evaluated a proof-of-concept prototype to demonstrate VideoPoseVR's interaction possibilities and use cases. The study results suggest that the prototype was easy to learn and use and that it could be used to quickly prototype immersive environments for applications such as entertainment, skills training, and crowd simulations.
# XR # computer vision
VideoPoseVR: Authoring Virtual Reality Character Animations with Online Videos
Cheng-Yao Wang, Qian Zhou, George Fitzmaurice, Fraser Anderson
PACM HCI (ISS 2022)
TL;DR: VideoPoseVR enables VR users to author character animations by reconstructing 3D human motion from online videos.
2021
Shared Realities: Avatar Identification and Privacy Concerns in Reconstructed Experiences
Cheng-Yao Wang, Sandhya Sriram, Andrea Stevenson Won
PACM HCI (CSCW 2021)
This paper investigates how people identify with reconstructed avatars and how privacy concerns shape sharing preferences in socially relived virtual reality experiences.
[Abstract] [DOI] [Paper] [Video]
# XR # Collaboration
Shared Realities: Avatar Identification and Privacy Concerns in Reconstructed Experiences
Cheng-Yao Wang, Sandhya Sriram, Andrea Stevenson Won
PACM HCI (CSCW 2021)
TL;DR: This paper investigates how people identify with reconstructed avatars and how privacy concerns shape sharing preferences in socially relived virtual reality experiences.
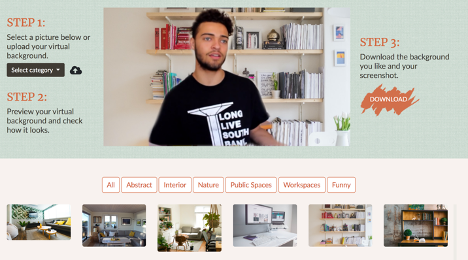
Hide and Seek: Choices of Virtual Backgrounds in Video Chats and Their Effects on Perception
Angel Hsing-Chi Hwang, Cheng-Yao Wang, Yao-Yuan Yang, Andrea Stevenson Won
PACM HCI (CSCW 2021)
This paper examines how virtual background choices in video conferencing shape viewers’ social perceptions, revealing a consistent “muting effect” rather than intentional impression control.
[Abstract] [DOI] [Paper] [Video]
In two studies, we investigate how users choose virtual backgrounds and how these backgrounds influence viewers’ impressions. In Study 1, we built a web-based prototype that allowed users to apply different virtual backgrounds to their camera views and asked them to select backgrounds they believed would alter viewers’ perceptions of their personality traits. In Study 2, we applied these selected backgrounds to videos from the First Impression Dataset and conducted three online experiments on Amazon Mechanical Turk to compare personality trait ratings across three conditions: selected virtual backgrounds, original video backgrounds, and a gray screen background. Contrary to participants’ intentions, virtual backgrounds did not shift personality ratings in the desired direction. Instead, any use of virtual backgrounds produced a consistent “muting effect,” compressing extreme ratings toward the mean. We discuss implications for impression management, authenticity, and design of video-mediated communication systems.
# Computer Vision
Hide and Seek: Choices of Virtual Backgrounds in Video Chats and Their Effects on Perception
Angel Hsing-Chi Hwang, Cheng-Yao Wang, Yao-Yuan Yang, Andrea Stevenson Won
PACM HCI (CSCW 2021)
TL;DR: This paper examines how virtual background choices in video conferencing shape viewers’ social perceptions, revealing a consistent “muting effect” rather than intentional impression control.
2020

Movebox: Democratizing Mocap for the Microsoft Rocketbox Avatar Library
Mar Gonzalez-Franco, Zelia Egan, Matthew Peachey, Angus Antley, Tanmay Randhavane, Payod Panda, Yaying Zhang, Cheng-Yao Wang, Derek F. Reilly, Tabitha C. Peck
IEEE AIVR 2020
Movebox introduces an open-source, low-barrier motion capture toolbox that enables real-time and offline animation of high-quality avatars using a single depth sensor or RGB video.
This paper presents Movebox, an open-source toolbox for animating motion-captured movements onto the Microsoft Rocketbox avatar library. The system supports motion capture using a single depth sensor, such as Azure Kinect or Windows Kinect V2, enabling real-time avatar animation. In addition, Movebox supports offline motion extraction from RGB videos using deep learning-based computer vision techniques. The toolbox bridges differences in skeletal structures by converting transformations across systems with different joint hierarchies. Additional features include animation recording, playback, looping, audio-driven lip sync, blinking, avatar resizing, and finger and hand animation. We validate Movebox across multiple devices and discuss its capabilities and limitations based on user feedback, highlighting its potential to democratize avatar animation and motion capture workflows.
# XR Computer Vision
Movebox: Democratizing Mocap for the Microsoft Rocketbox Avatar Library
Mar Gonzalez-Franco, Zelia Egan, Matthew Peachey, Angus Antley, Tanmay Randhavane, Payod Panda, Yaying Zhang, Cheng-Yao Wang, Derek F. Reilly, Tabitha C. Peck
IEEE AIVR 2020
TL;DR: Movebox introduces an open-source, low-barrier motion capture toolbox that enables real-time and offline animation of high-quality avatars using a single depth sensor or RGB video.

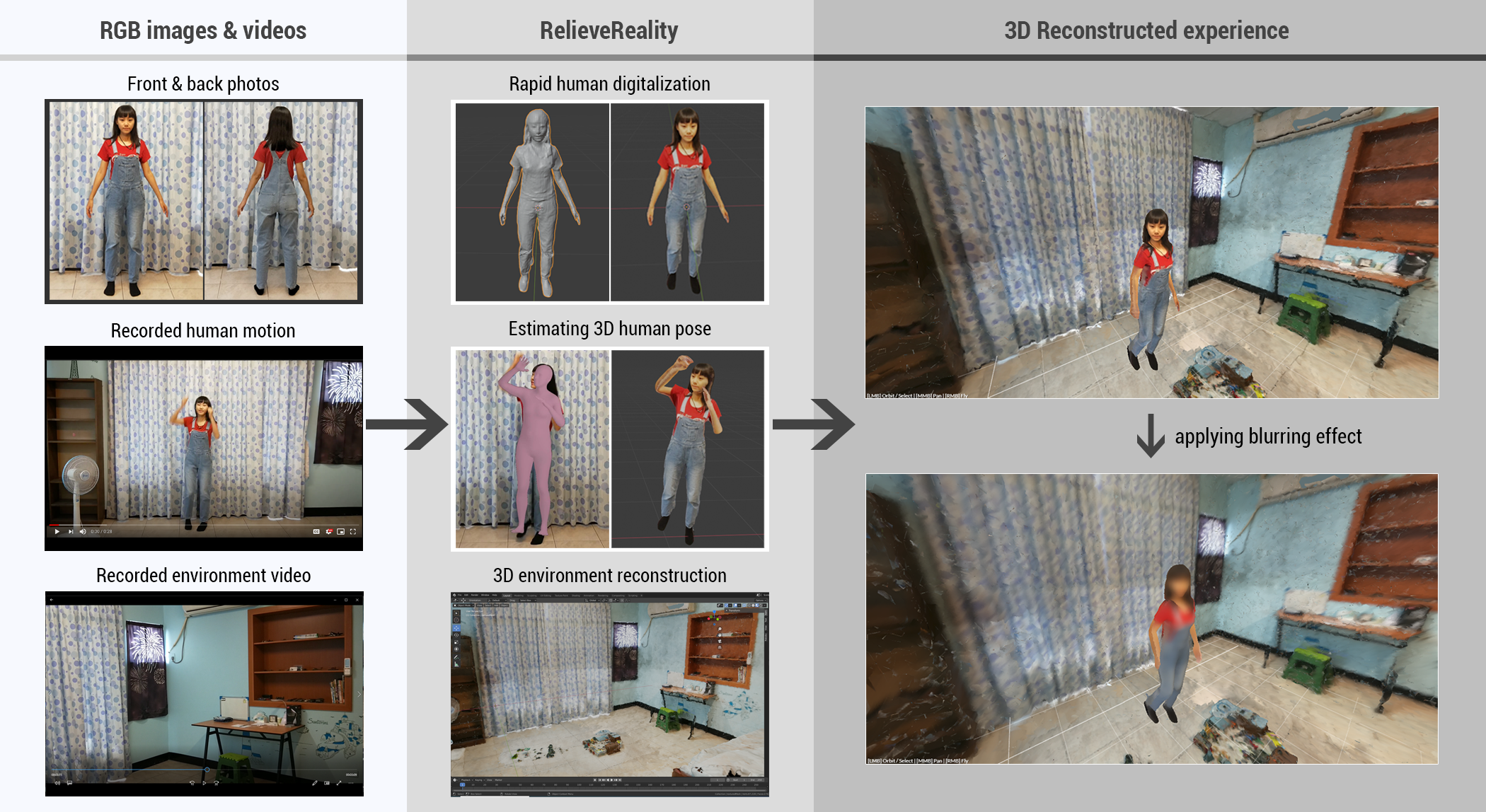
ReliveReality: Enabling Socially Reliving Experiences in Virtual Reality via a Single RGB Camera
Cheng-Yao Wang, Shengguang Bai, Andrea Stevenson Won
IEEE VRW 2020
ReliveReality enables people to socially relive past experiences in VR by reconstructing people and environments from a single RGB camera and supporting multi-user exploration.
We present ReliveReality, a novel experience-sharing method that transforms traditional photo and video memories into socially relivable 3D experiences in virtual reality. ReliveReality leverages deep learning-based computer vision techniques to reconstruct clothed humans, estimate multi-person 3D pose, and recover 3D environments using only a single RGB camera. Integrated into a networked multi-user VR environment, ReliveReality allows multiple users to enter a reconstructed past experience together, freely navigate it, and relive memories from different perspectives. We describe the system’s technical implementation and discuss broader implications of reconstructing and sharing personal experiences in VR, particularly with respect to privacy.
# XR
ReliveReality: Enabling Socially Reliving Experiences in Virtual Reality via a Single RGB Camera
Cheng-Yao Wang, Shengguang Bai, Andrea Stevenson Won
IEEE VRW 2020
TL;DR: ReliveReality enables people to socially relive past experiences in VR by reconstructing people and environments from a single RGB camera and supporting multi-user exploration.

Again, Together: Socially Reliving Virtual Reality Experiences When Separated
Cheng-Yao Wang, Mose Sakashita, Upol Ehsan, Jingjin Li, Andrea Stevenson Won
CHI 2020
Again, Together introduces ReliveInVR, a system that enables people to socially relive past VR experiences together, even when separated in time or space.
[Abstract] [DOI] [Paper] [Video]
To share a virtual reality (VR) experience remotely together, users typically record videos from an individual’s point of view and co-watch them later. However, video-based sharing limits users to the original capture perspective. We present ReliveInVR, a time-machine-like VR experience sharing system that allows multiple users to relive a recorded VR experience together while freely exploring it from any viewpoint. We conducted a 1×3 within-subject study with 26 dyads comparing ReliveInVR to co-watching 360-degree videos on desktop and in VR. Results show that ReliveInVR led to higher immersion, stronger social presence, and better understanding of shared experiences. Participants also reported discovering unnoticed details together and found the experience more fulfilling. We discuss design implications for asynchronous and remote sharing of immersive VR experiences.
# XR
Again, Together: Socially Reliving Virtual Reality Experiences When Separated
Cheng-Yao Wang, Mose Sakashita, Upol Ehsan, Jingjin Li, Andrea Stevenson Won
CHI 2020
TL;DR: Again, Together introduces ReliveInVR, a system that enables people to socially relive past VR experiences together, even when separated in time or space.
2019
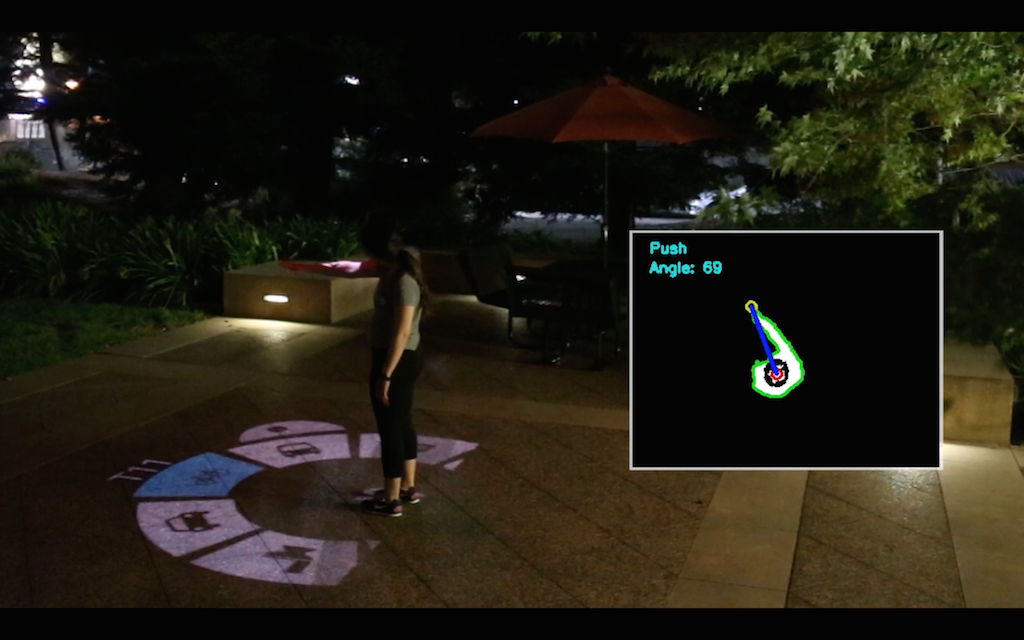
Drone.io: A Gestural and Visual Interface for Human-Drone Interaction
Jessica R. Cauchard, Alex Tamkin, Cheng-Yao Wang, Luke Vink, Michelle Park, Tommy Fang, James A. Landay
HRI 2019
Drone.io introduces a body-centric, projected graphical interface that enables intuitive gestural interaction with drones using simple, natural movements.
[Abstract] [DOI] [Paper] [Video]
Drones are becoming increasingly common and are used to support people in a variety of tasks, such as photography, in social and interactive contexts. We introduce drone.io, a projected body-centric graphical user interface for human-drone interaction that provides both input and output directly on the drone. Using only two simple gestures, users can interact with a drone in a natural and learnable manner. Drone.io is the first human-drone graphical interface embedded on a drone, enabling real-time feedback and control without external devices. We describe the design process behind drone.io and present both a proof-of-concept implementation and a fully functional prototype in a drone tour-guide scenario. We evaluated drone.io through three user studies (N = 27), demonstrating that participants were able to use the interface effectively with minimal prior training. This work contributes to human-robot interaction and advances research on intuitive human-drone interaction.
# Computer Vision
Drone.io: A Gestural and Visual Interface for Human-Drone Interaction
Jessica R. Cauchard, Alex Tamkin, Cheng-Yao Wang, Luke Vink, Michelle Park, Tommy Fang, James A. Landay
HRI 2019
TL;DR: Drone.io introduces a body-centric, projected graphical interface that enables intuitive gestural interaction with drones using simple, natural movements.
2018

RoMA: Interactive Fabrication with Augmented Reality and a Robotic 3D Printer
Huaishu Peng, Jimmy Briggs, Cheng-Yao Wang, Kevin Guo, Joseph Kider, Stefanie Mueller, Patrick Baudisch, François Guimbretière
CHI 2018
RoMA combines augmented reality and robotic 3D printing to enable interactive, in-situ fabrication where digital design and physical construction evolve together.
[Abstract] [DOI] [Paper] [Video]
We present the Robotic Modeling Assistant (RoMA), an interactive fabrication system that provides a fast, precise, hands-on, and in-situ modeling experience. As designers create models using an AR-based CAD editor, a robotic 3D printer concurrently fabricates features within the same design volume. The partially printed physical artifact serves as a tangible reference that designers can directly build upon. RoMA introduces a proxemics-inspired handshake mechanism that allows designers to fluidly negotiate control with the robotic arm, enabling quick interruptions for inspection or modification and seamless handoffs for autonomous printing. By tightly integrating digital design, physical fabrication, and human–robot collaboration, RoMA allows designers to rapidly incorporate real-world constraints, extend existing objects, and create well-proportioned tangible artifacts. We conclude by discussing the strengths and limitations of the system and directions for future interactive fabrication workflows.
# XR
RoMA: Interactive Fabrication with Augmented Reality and a Robotic 3D Printer
Huaishu Peng, Jimmy Briggs, Cheng-Yao Wang, Kevin Guo, Joseph Kider, Stefanie Mueller, Patrick Baudisch, François Guimbretière
CHI 2018
TL;DR: RoMA combines augmented reality and robotic 3D printing to enable interactive, in-situ fabrication where digital design and physical construction evolve together.
2015

PalmType: Using Palms as Keyboards for Smart Glasses
Cheng-Yao Wang, Wei-Chen Chu, Po-Tsung Chiu, Min-Chieh Hsiu, Yih-Harn Chiang, Mike Y. Chen
MobileHCI 2015
PalmType introduces palm-based text input for smart glasses, enabling eyes-free typing by leveraging users’ proprioception and lightweight wearable sensing.
[Abstract] [DOI] [Paper] [Video]
We present PalmType, a text input technique that uses the user’s palm as an interactive keyboard for smart wearable displays such as Google Glass. PalmType leverages users’ innate proprioceptive ability to accurately locate regions on their palms and fingers without visual attention, while providing minimal visual feedback through the wearable display. With wrist-worn sensors and head-mounted displays, PalmType enables typing without requiring users to hold any devices or look at their hands. Through design sessions with six participants, we examined how users naturally map a QWERTY keyboard layout onto their palms. We then conducted a 12-participant user study using Google Glass and a Vicon motion tracking system to evaluate typing performance and user preference. Results show that PalmType with an optimized QWERTY layout is 39% faster than touchpad-based text entry techniques and preferred by 92% of participants. We further demonstrate the feasibility of PalmType through a functional prototype using a wrist-worn array of infrared sensors to detect finger positions and taps.
# XR Computer Vision
PalmType: Using Palms as Keyboards for Smart Glasses
Cheng-Yao Wang, Wei-Chen Chu, Po-Tsung Chiu, Min-Chieh Hsiu, Yih-Harn Chiang, Mike Y. Chen
MobileHCI 2015
TL;DR: PalmType introduces palm-based text input for smart glasses, enabling eyes-free typing by leveraging users’ proprioception and lightweight wearable sensing.
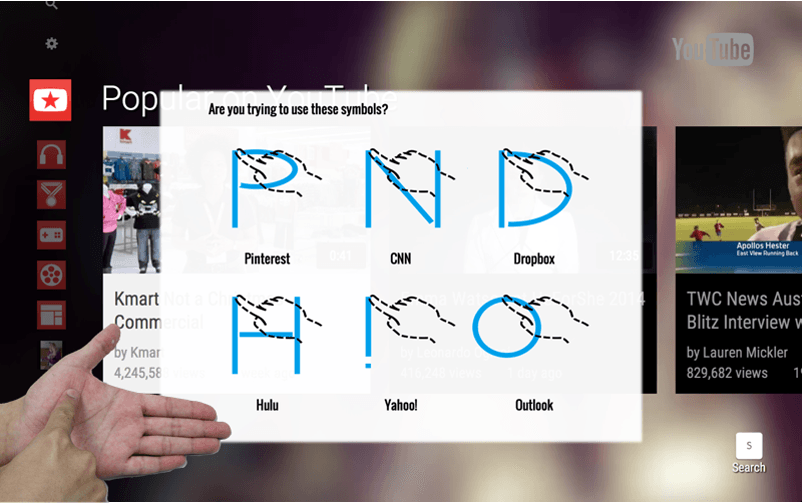
PalmGesture: Using Palms as Gesture Interfaces for Eyes-Free Input
Cheng-Yao Wang, Min-Chieh Hsiu, Po-Tsung Chiu, Chiao-Hui Chang, Liwei Chan, Bing-Yu Chen, Mike Y. Chen
MobileHCI 2015
PalmGesture investigates palm-based gesture input for wearables, enabling accurate eyes-free interaction through stroke gestures drawn directly on the palm.
[Abstract] [DOI] [Paper] [Video]
We explore eyes-free gesture interaction on the palm, allowing users to interact with wearable devices by drawing stroke gestures without visual attention. Through a 24-participant user study, we examined how people draw palm gestures with different characteristics, including regions, orientations, and starting points. Based on these findings, we propose two palm-based gesture interaction techniques that improve robustness and usability for eyes-free input. To demonstrate feasibility, we implemented EyeWrist, a wrist-mounted prototype that detects palm gestures using an infrared camera and a laser-line projector. A preliminary evaluation shows that EyeWrist supports graffiti-style letters and multi-stroke gestures with over 90% recognition accuracy. Our results indicate that palms are a viable and expressive surface for eyes-free gestural interaction on wearable devices.
# XR
PalmGesture: Using Palms as Gesture Interfaces for Eyes-Free Input
Cheng-Yao Wang, Min-Chieh Hsiu, Po-Tsung Chiu, Chiao-Hui Chang, Liwei Chan, Bing-Yu Chen, Mike Y. Chen
MobileHCI 2015
TL;DR: PalmGesture investigates palm-based gesture input for wearables, enabling accurate eyes-free interaction through stroke gestures drawn directly on the palm.
2014
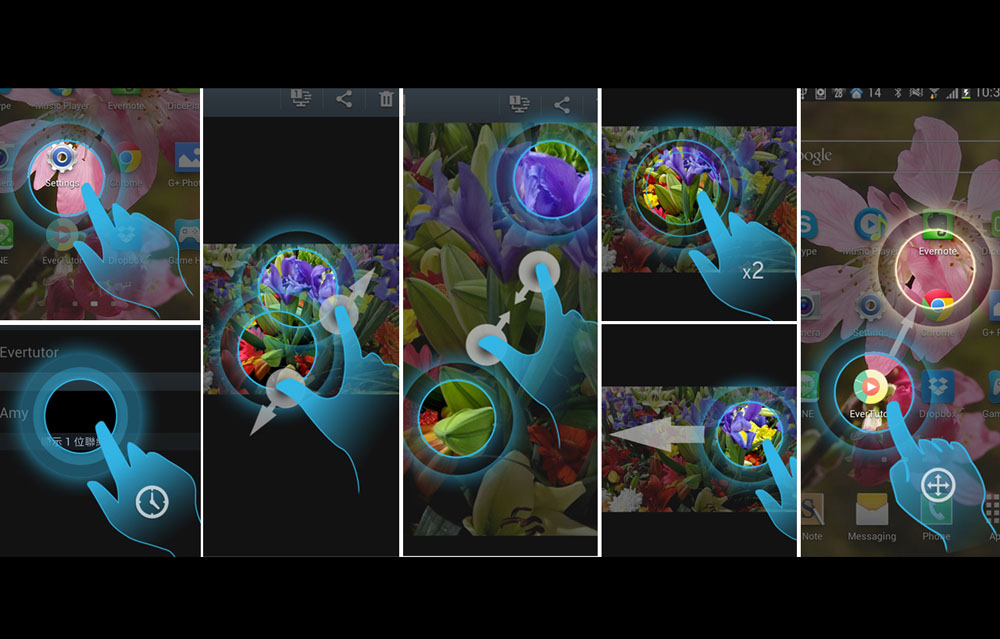
Evertutor: Automatically Creating Interactive Guided Tutorials on Smartphones by User Demonstration
Cheng-Yao Wang, Wei-Chen Chu, Hou-Ren Chen, Chun-Yen Hsu, Mike Y. Chen
CHI 2014
Evertutor automatically generates interactive, step-by-step smartphone tutorials by learning directly from user demonstrations, significantly reducing authoring effort and improving task completion speed for users.
[Abstract] [DOI] [Paper] [Video]
We present EverTutor, a system that automatically generates interactive tutorials on smartphones from user demonstrations. For tutorial authors, EverTutor simplifies tutorial creation; for tutorial users, it provides contextual step-by-step guidance while avoiding frequent context switching between tutorials and primary tasks. EverTutor records low-level touch events to detect gestures and identify on-screen targets during demonstrations. When a tutorial is browsed, the system uses vision-based techniques to locate target regions and overlays corresponding input prompts contextually. It also identifies the correctness of users’ interactions to guide them step by step. We conducted a 6-person user study on tutorial creation and a 12-person user study on tutorial browsing, comparing EverTutor’s interactive tutorials to static and video tutorials. Results show that creating tutorials with EverTutor is simpler and faster, while users completed tasks 3–6× faster with interactive tutorials across age groups. Additionally, 83% of users preferred the interactive tutorials, rating them as the easiest to follow and understand.
# XR # Computer Vision
Evertutor: Automatically Creating Interactive Guided Tutorials on Smartphones by User Demonstration
Cheng-Yao Wang, Wei-Chen Chu, Hou-Ren Chen, Chun-Yen Hsu, Mike Y. Chen
CHI 2014
TL;DR: Evertutor automatically generates interactive, step-by-step smartphone tutorials by learning directly from user demonstrations, significantly reducing authoring effort and improving task completion speed for users.